

DMOZ − historia o ludziach próbujących uporządkować sieć
Katalog internetowy DMOZ* (Open Directory Project, ODP) był zbiorem milionów hiperłączy, skategoryzowanych i doglądanych przez społeczność wolontariuszy z całego świata. DMOZ oddano do użytku w czerwcu 1998 roku jako GnuHoo**. Jeszcze w tym samym roku nazwę katalogu zmieniono na NewHoo, co było konsekwencją protestu złożonego przez Free Software Foundation, która sponsorowała projekt GNU [Sullivan 2017].
*nazwa pochodzi od directory.mozilla.org; DMOZ is an acronym for Directory Mozilla
**gnuhoo.com, nazwa pochodzi od słów GNU i Yahoo
Zawartość katalogu była udostępniana na licencji Open Content, co oznaczało, że nie pobierano opłat warunkujących wprowadzenie adresu strony internetowej do katalogu i/lub używanie danych, które udostępniał. Także obecnie zasoby otwartego katalogu są udostępniane bezpłatne dla każdego, kto zgadza się używać ich zgodnie z licencją. Pod koniec 1998 roku katalog NewHoo został sprzedany firmie Netscape, która zdecydowała o zmianie nazwy na ODP-DMoz. W 2000 roku Open Directory Project stał się własnością AOL (co można zaobserwować na stronie głównej katalogu, gdzie w 2000 roku pojawiło się logo AOL).
Katalog, nie wyszukiwarka
Celem Open Directory Project było utworzenie najbardziej wszechstronnego katalogu w sieci przy pomocy armii redaktorów-ochotników. Koncepcja ta zakładała społeczną odpowiedzialność za sieć. Przyświecało jej założenie, że każdy użytkownik Internetu może zorganizować niewielką część sieci i zaprezentować ją pozostałym użytkownikom, skupiając się jedynie na wartościowych treściach.
Zamknięcie katalogu DMOZ stało się symbolem końca czasów, kiedy ludzie własnymi rękami próbowali uporządkować sieć.
DMOZ Open Directory Project był najbardziej wszechstronnym katalogiem internetowym redagowanym przez ludzi tworzących globalną społeczność redaktorów-ochotników. DMOZ zapewniał podstawowe usługi katalogowe dla najpopularniejszych portali i wyszukiwarek internetowych, w tym AOL Search, Netscape Search, Google, Lycos, DirectHit i HotBot oraz dla setek innych. Zasoby katalogu były hostowane i administrowane przez firmę Netscape Communication Corp. [Graham 2004]. DMOZ był katalogiem internetowym, a nie wyszukiwarką. Celem DMOZ była kategoryzacja i udostępnianie wykazu witryn internetowych. Witryny nie były promowane ani optymalizowane pod kątem wyszukiwarek.
DMOZ był po prostu dostawcą danych.
Od samego początku DMOZ był przykładem hierarchicznej klasyfikacji treści [Zaihrayeu i in. 2007]. Dzięki Internet Archive możliwe jest zapoznanie się z historią katalogu (ryc. 1). W lipcu 2000 roku DMOZ posiadał 1,891,380 witryn, 26,717 redaktorów oraz 287,428 kategorii. W kwietniu 2005 roku DMOZ posiadał już ponad 4 miliony witryn, 67,576 redaktorów oraz ponad 590,000 kategorii. Licznik katalogu zatrzymał się na około 3,861,366 witryn udostępnionych w 90 różnych językach (dane z 1 marca 2017 roku) (źródło: Internet Archive).
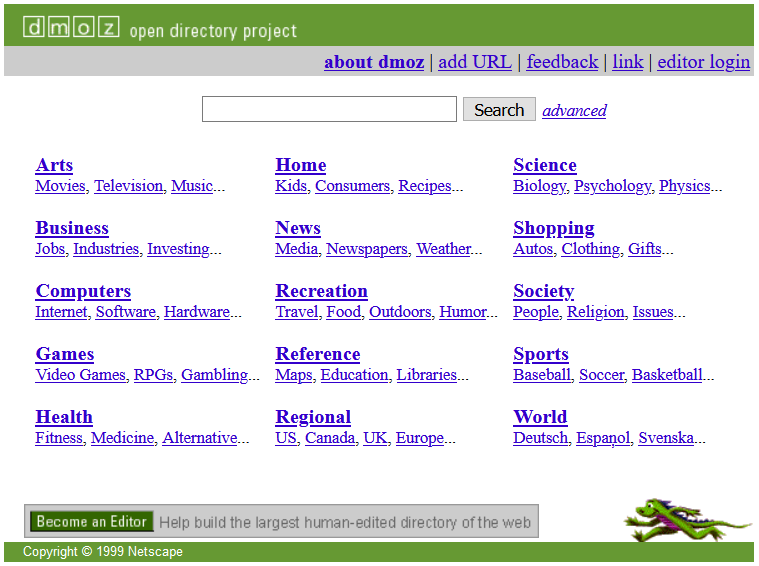 Rycina 1. DMOZ ponad 20 lat temu (2000 rok). Źródło: Internet Archive.
Rycina 1. DMOZ ponad 20 lat temu (2000 rok). Źródło: Internet Archive.
DMOZ został zamknięty 17 marca 2017 roku po 19 latach działalności (ryc. 2), jednak jego misja jest kontynuowana przez społeczność zrzeszoną wokół projektu Curlie (https://curlie.org). Curlie to największy redagowany przez ludzi katalog internetowy. Jest tworzony i utrzymywany przez globalną społeczność wolontariuszy. Curlie jest kontynuacją projektu Open Directory Project (ODP), znanego jako DMOZ.
 Rycina 2. Od 17 marca 2017 roku katalog Dmoz.org nie jest już dostępny. Źródło: Internet Archive (kopia DMOZ z 1 lipca 2017 r.).
Rycina 2. Od 17 marca 2017 roku katalog Dmoz.org nie jest już dostępny. Źródło: Internet Archive (kopia DMOZ z 1 lipca 2017 r.).
DMOZ był ogromnym, ręcznie edytowanym katalogiem witryny internetowych, który zawierał miliony adresów URL pogrupowanych w 15 głównych kategoriach. Katalog zawierał strony internetowe w kilkudziesięciu językach [Gulli i Signorini 2005]. Pomimo, że DMOZ został zamknięty w 2017 roku kopia plików* pozostaje dostępna i jest wykorzystywana do różnych celów, w tym naukowych [Zaeem i Barber 2020, Matošević i in. 2021].
Misja DMOZ jest kontynuowana przez społeczność zrzeszoną wokół projektu Curlie.
Witryny internetowe zgromadzone w katalogu DMOZ były i nadal są źródłem danych dla wielu badań, np. szacowania rozmiaru publicznej indeksowanej sieci [Gulli i Signorini 2005]; testowania różnych klasyfikacji i sposobów katalogowania danych [Zaihrayeu i in. 2007]; do badania polityk prywatności zamieszczonych na stronach internetowych [Zaeem i Barber 2020] lub do klasyfikowania witryn w zależności od stopnia optymalizacji dla wyszukiwarek internetowych (SEO) [Matošević i in. 2021]. Ponadto DMOZ jest często używany w badaniach z zakresu wyszukiwania informacji i klasyfikowania stron internetowych [Lee i in. 2015], streszczania treści stron internetowych [Zhang i in. 2004] i wyodrębniania słów kluczowych [Mostafa 2013].
Źródła
- Graham, A. (2004). DMOZ – Directory Mozilla The Open Directory Project, http://dmoz.org. The Physics Teacher, 42(4), 255-255. https://doi.org/10.1119/1.1696605
- Gulli, A., Signorini, A. (2005). The indexable web is more than 11.5 billion pages. In Special interest tracks and posters of the 14th international conference on World Wide Web (pp. 902-903). https://doi.org/10.1145/1062745.1062789
- Lee, J.-H., Yeh, W.-C., Chuang, M.C. (2015). Web page classification based on a simplified swarm optimization. Appl. Math. Comput., 270, 13-24. https://doi.org/10.1016/j.amc.2015.07.120
- Matošević, G, Dobša, J, Mladenić, D. (2021). Using Machine Learning for Web Page Classification in Search Engine Optimization. Future Internet, 13(1), 9. https://doi.org/10.3390/fi13010009
- Mostafa, L. (2013). Webpage Keyword Extraction Using Term Frequency. Int. J. Comput. Theory Eng., 5(1), 174. https://doi.org/10.7763/IJCTE.2013.V5.672
- Sullivan, D. (2017). RIP DMOZ: The Open Directory Project is closing. Search Engine Land. https://searchengineland.com/rip-dmoz-open-directory-project-closing-270291
- Zaeem, R. N., Barber, K. S. A (eds.) (2020). Anonymous Author(s). (2018). A Large Publicly Available Corpus of Website Privacy Policies Based on DMOZ. In Woodstock ’18: ACM Symposium on Neural Gaze Detection, June 3-5, 2018, Woodstock, NY. ACM, New York, NY, USA. https://doi.org/10.1145/1122445.1122456
- Zaihrayeu, I., Sun, L., Giunchiglia, F., Pan, W., Ju, Q., Chi, M., Huang, X. (2007). From Web Directories to Ontologies: Natural Language Processing Challenges. In: Aberer K. et al. (eds) The Semantic Web. ISWC 2007, ASWC 2007. Lecture Notes in Computer Science, vol 4825. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-76298-0_45
- Zhang, Y., Zincir-Heywood, N., Milios, E. (2004). Term-Based Clustering and Summarization of Web Page Collections. In: Tawfik A.Y., Goodwin S.D. (eds) Advances in Artificial Intelligence. Canadian AI 2004. Lecture Notes in Computer Science, Vol. 3060. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-24840-8_5