

Cyfrowe dziedzictwo: katalogi witryn i bezpłatny hosting
Katalogi witryn najczęściej pełniły funkcję tzw. zaplecza dla pozycjonowania, przez co były źle oceniane przez algorytmy wyszukiwarek. Miało to niemałe znaczenie przy plasowaniu witryny w wynikach wyszukiwania. W konsekwencji na znaczeniu straciły serwisy agregujące hiperłącza (tzw. farmy linków) oraz tzw. presell pages, które nie spełniały oczekiwań użytkowników.
Pełna treść publikacji: Król, K., Zdonek, D. (2022). Digital artefacts of rural tourism: the case study of Poland. Global Knowledge, Memory and Communication. https://doi.org/10.1108/GKMC-03-2022-0052
Wraz ze zmianami w algorytmach wyszukiwarek zmienił się rynek usług pozycjonowania, optymalizacji witryn dla wyszukiwarek internetowych SEO, a także marketingu internetowego i reklamy. Zmieniły się także praktyki tworzenia i publikowania witryn internetowych. Wielu usługodawców zrezygnowało ze świadczenia bezpłatnych usług hostingowych oraz zamknęło katalogi witryn. Niedługo po ich likwidacji stały się one przedmiotem zainteresowania archeologii Internetu, rozumianej jako badanie ujawniających się w przeszłości sposobów publikacji danych i zmian jakie dokonały się w zakresie wzorców graficznych i standardów projektowych.
Cyfrowe dziedzictwo: katalogi witryn i bezpłatny hosting
Jeszcze do niedawna liczba hiperłączy była jednym z najważniejszych czynników kształtujących rankingi wyszukiwarek, co spowodowało pojawienie się nowego rodzaju spamu w postaci farm linków oraz witryn typu presell pages. Spamowanie linkami (link spamming) polegało na zawyżaniu rankingu określonej witryny, poprzez sztuczne, celowe namnażanie licznych stron odsyłających. Wiele treści internetowych powstawało nie dla użytkowników, lecz w celu wpływania na algorytmy wyszukiwarek i uzyskiwania wyższej niż zasłużona pozycji w wynikach wyszukiwania [Tung i in. 2006]. Były to działania na tyle skuteczne, że znalazły wielu naśladowców. Aby utrzymać jakość wyników wyszukiwania, dostawcy wyszukiwarek przeciwstawili się tym praktykom i udoskonalili algorytmy rankingowe [Drost i Scheffer 2005].
 Według wykazu sporządzonego przez Moz historia zmian w algorytmach Google rozpoczęła się już ponad 20 lat temu, tj. w 2000 roku. [więcej]
Według wykazu sporządzonego przez Moz historia zmian w algorytmach Google rozpoczęła się już ponad 20 lat temu, tj. w 2000 roku. [więcej]
Zmiany w algorytmach wyszukiwania sprawiły, że popularne dawniej katalogi witryn internetowych zyskały status farm linków. W konsekwencji ich twórcy (wydawcy) próbowali nadać im wartość, tj. sprawić, że będą bardziej przydatne, np. poprzez dodawanie obszerniejszych opisów do katalogowanych witryn. Działania te były jednak czasochłonne i nieskuteczne. Niektóre katalogi komercyjne były tak duże, że ich modernizacja była praktycznie niemożliwa i (lub) całkowicie nieopłacalna. Z tych powodów większość katalogów zlikwidowano przed 2020 rokiem.
Katalogi stron internetowych w Polsce
Przykładem katalogu witryn internetowych, który utworzono w Polsce w 1995 roku jest Wirtualna Polska – Katalog stron WWW, który szybko przerodził się w portal horyzontalny (Ryc. 1). W 2018 roku Wirtualna Polska podała, że z przyczyn organizacyjnych zaprzestaje świadczenia usług poprzez serwis katalog.wp.pl. W związku z tym wypowiedzeniu uległy wszystkie zawarte wcześniej umowy o świadczenie usług w serwisie katalog.wp.pl. Od dnia 7 stycznia 2019 roku nie było możliwości dodawania nowych i modyfikowania zamieszczonych już wpisów. Całkowite wygaszenie serwisu nastąpiło 31 stycznia 2019 roku, chociaż witryna katalog.wp.pl dostępna była jeszcze do kwietnia tego roku.
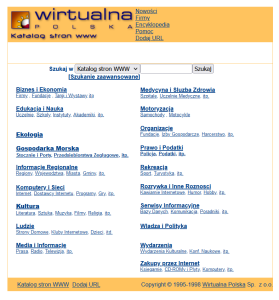
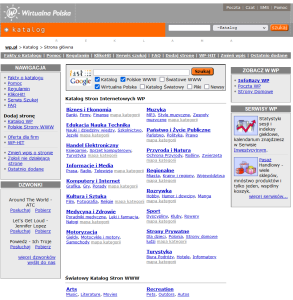
Rycina 1. Od lewej: Wirtualna Polska – Katalog stron WWW – lata 1998 oraz 2002. Źródło: Internet Archive.
Alternatywą dla katalogu Wirtualna Polska był katalog INTERIA.pl, który szybko przekształcił się w serwis pn „Szukaj – Centrum wyszukiwania”, a następnie „Wyszukiwarka INTERIA.PL – Katalog polski”. Wyszukiwarka funkcjonowała równolegle z katalogiem witryn (ryc. 2). Katalog INTERIA.pl spotkał podobny los, jak większość katalogów funkcjonujących przy portalach internetowych – 1 marca 2020 roku serwis został zamknięty. Razem z nim z zasobów Internetu zniknęły wykazy unikalnych stron internetowych, spośród których wiele miało niepowtarzalny charakter.
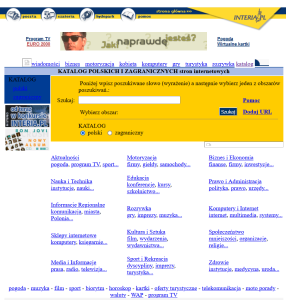
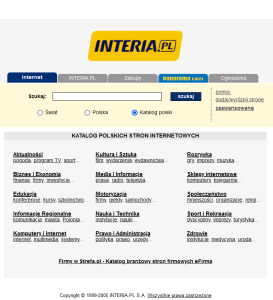
Rycina 2. Od lewej: INTERIA.pl – Katalog stron WWW – rok 2000 oraz 2005. Źródło: Internet Archive.
Portale Republika WWW oraz Miasto WWW
Ponad 20 lat temu portal Republika WWW (portal.republika.pl; republika.onet.pl) był reklamowany jako „Pierwszy w Polsce portal społeczności internetowych”. Witryna była wykonana zgodnie ze specyfikacją HTML 3.2 FINAL i zajmowała jedynie 860px szerokości ekranu, jednak należy pamiętać, że używano wtedy monitorów CRT o przekątnej 15 cali. Już w 1999 roku portal zachęcał do utworzenia za jego pomocą własnej strony internetowej, co nie wiązało się z opłatami abonamentowymi. Było to nowością dla użytkowników, którzy chcieli zaistnieć w sieci i odpowiedzią na rozwój technologiczny. Na świecie funkcjonowały już bezpłatne usługi hostingowe, takie jak np. GeoCities [Milligan 2017] lub AOL Hometown [Thelwall 2009]. Integralną częścią serwisu Republika WWW był katalog witryn internetowych. W katalogu umieszczono witryny pogrupowane tematycznie, począwszy od farmacji, skończywszy na bazie noclegowej.
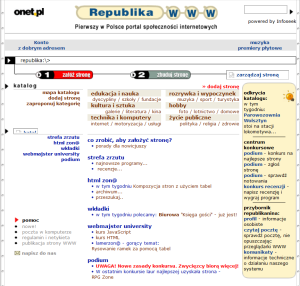
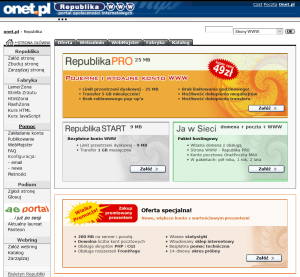
Rycina 3. Od lewej: szata graficzna portalu Republika WWW w 2000 roku oraz w 2003 roku. Źródło: Internet Archive.
W 2016 roku rozpoczął się stopniowo realizowany proces wyłączania poszczególnych usług portalu Republika WWW. W dniu 1 lipca 2017 roku wyłączono możliwość logowania się w serwisie republika.onet.pl, a także zarządzania stronami za pomocą narzędzia WebAdmin. Aktualizowanie stron internetowych i zarządzanie nimi było możliwe przy użyciu klasycznego programu FTP. W dniu 1 marca 2018 roku serwis został zamknięty (ryc. 4).

Rycina 4. Komunikat o zamknięciu serwisu Republika WWW. Źródło: Internet Archive.
Przez lata serwis Miasto WWW przedstawiany był jako „twoje miejsce w Internecie”. Umożliwić miały to bezpłatne usługi hostingowe oraz serwis STREFA.pl. Oprawa graficzna serwisu zmieniła się dopiero w 2016 roku, kiedy to z powodu modernizacji chwilowo zablokowano możliwość zakładania nowych kont. Po modernizacji Miasto WWW utraciło swój dotychczasowy charakter i dało się odczuć kierunek zmian, które to podążały w stronę komercyjnych usług hostingowych. Rola społeczna serwisu, jako przestrzeni dla spotkań, dyskusji i wymiany poglądów zakończyła się wraz z ekspansją serwisów społecznościowych. Z kolei katalogi witryn zostały zastąpione przez wyszukiwarki z coraz doskonalszymi algorytmami wyszukiwania.
Formuła serwisu Miasto WWW wyczerpała się całkowicie w 2018 roku. Z dniem 21 maja 2018 roku serwis miasto.interia.pl został zamknięty. 19 kwietnia 2018 roku konta i strony w domenach interiowo.pl przestały działać. 21 maja 2018 roku konta i strony w domenach strefa.pl zostały usunięte.
Pewna epoka w historii polskiego Internetu dobiegła końca
Katalogi witryn były tak naprawdę bazami danych. Wraz z likwidacją katalogów oraz bezpłatnych usług hostingowych skasowane zostały nie tylko pliki, ale także niepowtarzalne wykazy (spisy) nierzadko unikalnych adresów witryn internetowych. W konsekwencji nie występują one w wynikach wyszukiwania. Pokazuje to jak ważną rolę odgrywają instytucje pokroju Internet Archive, które archiwizują cyfrowe zasoby z całego świata. Dzięki ich pracy dostępnych jest wiele cyfrowych artefaktów. Może to być jednak niewystarczające. Na nic zda się pozyskanie, zarchiwizowanie i przechowywanie terabajtów danych, jeżeli zaniknie świadomość istnienia i wartości tych danych. Dlatego warto dokumentować zjawiska, które stanowią fragment historii, w tym przypadku – historii polskiego Internetu.
Zastrzeżenie. Wszystkie wyżej wymienione znaki towarowe należą do swoich (odpowiednich) właścicieli. Nazwy firm i produktów użyte w tym opracowaniu służą wyłącznie do celów identyfikacyjnych.
Disclaimer. All trademarks and registered trademarks mentioned herein are the property of their respective owners. The company and product names used in this document are for identification purposes only.
The source of the figures: Internet Archive (https://archive.org/, accessed on 11 July 2022). Access to the Internet Archive’s Collections is provided at no cost and is granted for scholarship and research purposes only.
Źródła
- Drost I., Scheffer T. (2005) Thwarting the Nigritude Ultramarine: Learning to Identify Link Spam. In: Gama J., Camacho R., Brazdil P.B., Jorge A.M., Torgo L. (eds) Machine Learning: ECML 2005. ECML 2005. Lecture Notes in Computer Science, vol 3720. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11564096_14
- Milligan, I. (2017). Welcome to the web: The online community of GeoCities during the early years of the World Wide Web. In: Niels Brügger and Ralph Schroeder (eds.), The Web as History. London, UCL Press. https://doi.org/10.14324/111.9781911307563
- Thelwall, M. (2009). Social network sites: Users and uses. Advances in computers, 76, 19-73. https://doi.org/10.1016/S0065-2458(09)01002-X
- Tung, T. S., Yahaya, N. A., Mustapha, S. S. (2006). Multi-level Link Structure Analysis Technqiue for Detecting Link Farm Spam Pages. In 2006 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology Workshops (pp. 614-617). IEEE, Hong Kong, China. https://doi.org/10.1109/WI-IATW.2006.95